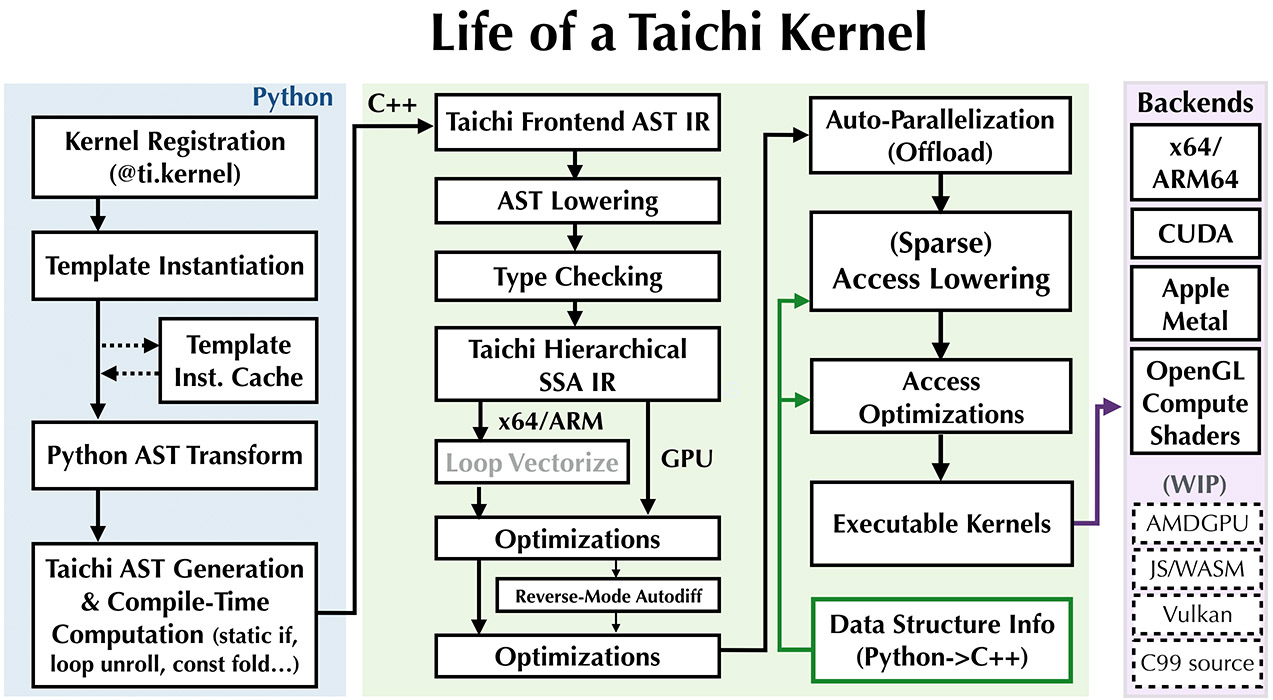
Life of a Taichi kernel¶
有时了解Taichi内核的生命周期会有所帮助。 简而言之,编译只会在第一次调用内核实例时发生。
The life cycle of a Taichi kernel has the following stages:
- 内核注册
- 模板实例化和缓存
- Python 抽象语法树转换 (AST: Abstact Syntax Tree )
- Taichi IR compilation, optimization, and executable generation
- 启动
让我们考虑以下简单内核:
@ti.kernel
def add(tensor: ti.template(), delta: ti.i32):
for i in tensor:
tensor[i] += delta
We allocate two 1D tensors to simplify discussion:
x = ti.var(dt=ti.f32, shape=128)
y = ti.var(dt=ti.f32, shape=16)
内核注册¶
当执行 ti.kernel 装饰器时,将注册一个名为 add 的内核。 具体来说,将记住 add 函数的Python抽象语法树(AST)。 在第一次调用 add 之前不会进行编译。
模板实例化和缓存¶
add(x, 42)
第一次调用 add 时,Taichi前端编译器将实例化内核。
When you have a second call with the same template signature (explained later), e.g.,
add(x, 1)
Taichi将直接重复使用之前编译的二进制文件。
用 ti.template() 提示的参数是模板参数,将引起模板实例化。 例如,
add(y, 42)
将导致 add 的新实例化。
注解
Template signatures are what distinguish different instantiations of a kernel template.
The signature of add(x, 42) is (x, ti.i32), which is the same as that of add(x, 1). Therefore, the latter can reuse the previously compiled binary.
The signature of add(y, 42) is (y, ti.i32), a different value from the previous signature, hence a new kernel will be instantiated and compiled.
注解
Many basic operations in the Taichi standard library are implemented using Taichi kernels using metaprogramming tricks. Invoking them will incur implicit kernel instantiations.
示例包括 x.to_numpy() 和 y.from_torch(torch_tensor)。 调用这些方程时,你将看到内核实例化,因为将生成Taichi内核来把繁重的工作分流给多个CPU内核/ GPU。
如前所述,第二次调用相同的操作时,缓存的已编译内核将被重用,并且不需要进一步的编译。
代码转换和优化¶
When a new instantiation happens, the Taichi frontend compiler (i.e., the ASTTransformer Python class) will transform the kernel body AST
into a Python script, which, when executed, emits a Taichi frontend AST.
Basically, some patches are applied to the Python AST so that the Taichi frontend can recognize it.
AST 的降阶过程 (lowering pass) 会将前端中间表示代码转换为分层静态单任务 (SSA: Static Single Assignment ) 的中间表示代码,从而可以用更多的过程进一步处理中间表示代码,例如
- 循环矢量化
- 类型推断和检查
- 一般简化,例如通用子表达式消除(CSE),无效指令消除(DIE),常数折叠和存储转发
- 降低访问权限
- 数据访问优化
- 反向模式自动微分(如果使用微分编程)
- 并行化和卸载
- 原子操作降级
即时(JIT)编译引擎¶
Finally, the optimized SSA IR is fed into backend compilers such as LLVM or Apple Metal/OpenGL shader compilers. The backend compilers then generate high-performance executable CPU/GPU programs.
内核启动¶
Taichi kernels will be ultimately launched as multi-threaded CPU tasks or GPU kernels.